Pandas
- Panel datas
- numpy와 통합하여 빠름





Series


DataFrame
loc, iloc, drop, reset_index, fill_value, lambda, map, apply, applymap, replace








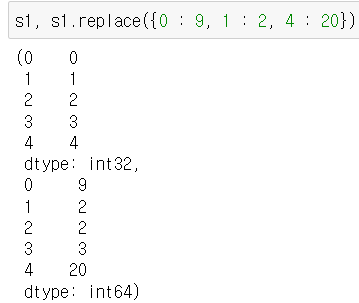

Built-in function
describe, unique, sort_values, corr, cov, corrwith, pd.options.display






Groupby
- split -> apply -> combine
groupby, hierarchical index, unstack, reset_index, swaplevel, sort_index, sort_values, get_group, aggregation, transform, filter




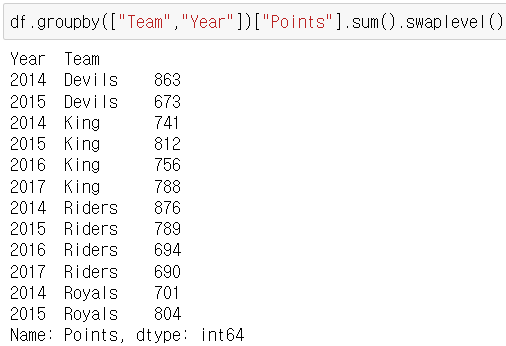









Pivot
- column에 labeling 값 추가 -> value에 aggregation
Crosstab
- pivot table의 특수한 형태, 두 col의 관계를 구할 때 사용
Merge
- pivot table의 특수한 형태, 두 col의 관계를 구할 때 사용

pd.merge(df_a, df_b, on='merge_key',how = 'how_join') # col 명이 다를 때
pd.merge(df_a, df_b, left_on='subject_id', right_on='subject_id', how = 'how_join') # col 명이 다를 때Join

Concat

Persistance
- pandas의 data를 저장하는 법
- DB, excel, pickle 등
'부스트캠프 AI Tech > Python' 카테고리의 다른 글
| Numpy (0) | 2022.01.23 |
|---|---|
| Data handling (0) | 2022.01.22 |
| Exception/File/Log handling (0) | 2022.01.21 |
| Module (0) | 2022.01.21 |
| Object Oriented Programming (0) | 2022.01.21 |

